Got Tired of MongoDB Full Text Index
We use MongoDB as our primary data source in Likeastore and went the way of MongoDB Full Text Search. Everything were fine initially, but after a while it became obvious that MongoDB FTS could not satisfy me any more.
I knew about search oriented storages as ElasticSearch, Sphinx, Solr, etc. but the migration process always seemed a bit scary to me. After a bit of elaboration I decided to go with Elastic and the migration was quite fun and not so difficult as I initially expected.
What’s wrong with MongoDB?
We are using MongoDB 2.4 and full text search is experimental feature there. By default, it’s turned off on production instances of MongoHQ. Anyway, it’s very easy to turn it on and run text commands against it. But we met it’s bottleneck when indexed collection start to grow (>3M documents).
We are doing a lot of inserts and if you have full text index, each insert triggers index re-calculation. Few weeks ago I’ve noticed huge performance issues of our DB. After first glance of monitoring information it’s was pretty clear that Locked index is >110% and a lot requests got timed-out. Application became low responsive.
It could be potentially solved by moving on more powerful server (more CPU and RAM) or by sharding database into few instances. Both costs money. Costs are something that I would like to avoid, if possible. It was time to move to specialized solution.
This is the reason to deploy ElasticSearch – put less strain on MongoDB and to use as an asynchronous index.
Migration plan
Before starting out, I’ve consulted with my guru Vinay Sahni and his experience of ElasticSeach in SupportFu. The general feedback on ElasticSeach was really nice. They don’t use any rivers instead use after_save hook of their ORM, so each time new document is created it’s pushed to ElasticSearch index.
I decided to go similar way, so my migration plan was:
- Export all existing documents to ElasticSearch.
- Correct the code and after each new insert send update to ElasticSearch.
In my situation it’s a bit simpler, by the fact, I have only one collection to index and major part of DB operations are inserts not updates, otherwise I believe using of river has more sense (and a more effort to setup).
Deploy instance on Digital Ocean
I’ve spin-up Digital Ocean droplet and used that great instructions for installation (btw, I recommend to install from Debian package, since it’s easier to run elastic as init.d service).
Just in 10 minutes you have working ElasticSeach cluster, ready to rock.
Migrate MongoDB data to ElasticSearch index
Then I needed to move about 12GB of data from my production MongoDB instance to Elastic. To accomplish that, I’ve created really simple tool – elaster. Elaster streams MongoDB collection into ElasticSearch index, based on configuration you provide.
I’ve installed nodejs on ElasticSeach server, cloned elaster there and run,
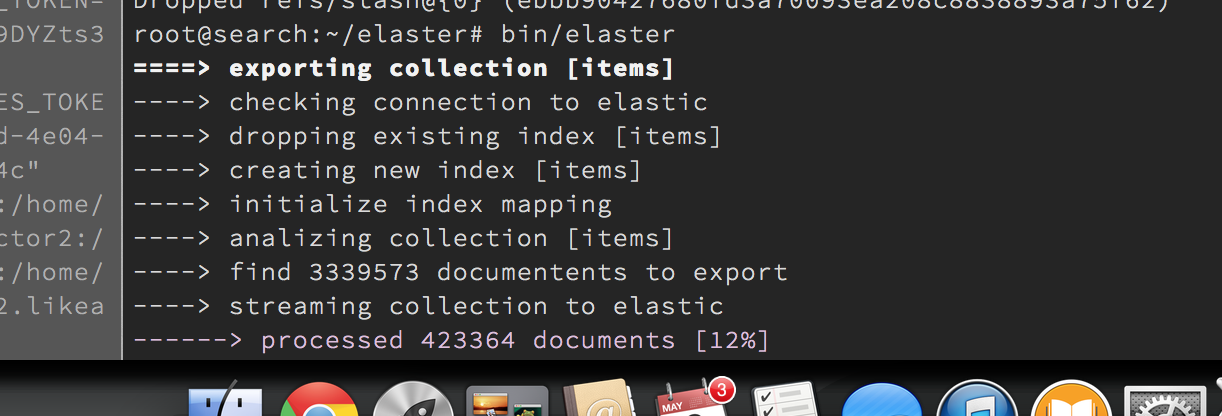
Both elaster and application code use elasticsearch npm package.
The whole process took ~2 hours.
Update the application code
Right after documents are inserted to MongoDB and initialized with _id, they are ready to be saved to index. I use bulk operation for that,
1
2
3
4
5
6
7
8
9
10
11
12
13
index: function (items, state, callback) {
if (!items || items.length === 0) {
return callback(null, items);
}
var commands = [];
items.forEach(function (item) {
commands.push({'index': {'_index': 'items', '_type': 'item', '_id': item._id.toString()}});
commands.push(item);
});
elastic.bulk({body: commands}, callback);
}
Simple search query
ElasticSearch comes with very nice Query DSL. I’m very new to the technology, so I’ve managed to create really simple query, which already gives quite nice results.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
function fullTextItemSearch (user, query, paging, callback) {
if (!query) {
return callback(null, { data: [], nextPage: false });
}
var page = paging.page || 1;
elastic.search({
index: 'items',
from: (page - 1) * paging.pageSize,
size: paging.pageSize,
body: {
query: {
filtered: {
query: {
'query_string': {
query: query
},
},
filter: {
term: {
user: user.email
}
}
}
}
}
}, function (err, resp) {
if (err) {
return callback(err);
}
var items = resp.hits.hits.map(function (hit) {
return hit._source;
});
callback(null, {data: items, nextPage: items.length === paging.pageSize});
});
}
It just uses query_string and filter term, to filter out results for given user. The interface of Search API remained the same, just instead of querying MongoDB, now we query ElasticSearch.
Summary
The main conclusion is – ElasticSearch is kind of technology that works out of the box. It’s very complex inside, but have great interface that hides all the complexity. First and good enough results can be archived very quickly.
In the same time, the technology requires time and effort to understand it and to use it right. I have absolutely no experience with full text search, so it’s really journey for me.
We use MongoDB as our primary data source in Likeastore and went the way of MongoDB Full Text Search. Everything were fine initially, but after a while it became obvious that MongoDB FTS could not satisfy me any more.
I knew about search oriented storages as ElasticSearch, Sphinx, Solr, etc. but the migration process always seemed a bit scary to me. After a bit of elaboration I decided to go with Elastic and the migration was quite fun and not so difficult as I initially expected.
What’s wrong with MongoDB?
We are using MongoDB 2.4 and full text search is experimental feature there. By default, it’s turned off on production instances of MongoHQ. Anyway, it’s very easy to turn it on and run text commands against it. But we met it’s bottleneck when indexed collection start to grow (>3M documents).
We are doing a lot of inserts and if you have full text index, each insert triggers index re-calculation. Few weeks ago I’ve noticed huge performance issues of our DB. After first glance of monitoring information it’s was pretty clear that Locked index is >110% and a lot requests got timed-out. Application became low responsive.
It could be potentially solved by moving on more powerful server (more CPU and RAM) or by sharding database into few instances. Both costs money. Costs are something that I would like to avoid, if possible. It was time to move to specialized solution.
This is the reason to deploy ElasticSearch – put less strain on MongoDB and to use as an asynchronous index.
Migration plan
Before starting out, I’ve consulted with my guru Vinay Sahni and his experience of ElasticSeach in SupportFu. The general feedback on ElasticSeach was really nice. They don’t use any rivers instead use after_save hook of their ORM, so each time new document is created it’s pushed to ElasticSearch index.
I decided to go similar way, so my migration plan was:
- Export all existing documents to ElasticSearch.
- Correct the code and after each new insert send update to ElasticSearch.
In my situation it’s a bit simpler, by the fact, I have only one collection to index and major part of DB operations are inserts not updates, otherwise I believe using of river has more sense (and a more effort to setup).
Deploy instance on Digital Ocean
I’ve spin-up Digital Ocean droplet and used that great instructions for installation (btw, I recommend to install from Debian package, since it’s easier to run elastic as init.d service).
Just in 10 minutes you have working ElasticSeach cluster, ready to rock.
Migrate MongoDB data to ElasticSearch index
Then I needed to move about 12GB of data from my production MongoDB instance to Elastic. To accomplish that, I’ve created really simple tool – elaster. Elaster streams MongoDB collection into ElasticSearch index, based on configuration you provide.
I’ve installed nodejs on ElasticSeach server, cloned elaster there and run,
Both elaster and application code use elasticsearch npm package.
The whole process took ~2 hours.
Update the application code
Right after documents are inserted to MongoDB and initialized with _id, they are ready to be saved to index. I use bulk operation for that,
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Simple search query
ElasticSearch comes with very nice Query DSL. I’m very new to the technology, so I’ve managed to create really simple query, which already gives quite nice results.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
It just uses query_string and filter term, to filter out results for given user. The interface of Search API remained the same, just instead of querying MongoDB, now we query ElasticSearch.
Summary
The main conclusion is – ElasticSearch is kind of technology that works out of the box. It’s very complex inside, but have great interface that hides all the complexity. First and good enough results can be archived very quickly.
In the same time, the technology requires time and effort to understand it and to use it right. I have absolutely no experience with full text search, so it’s really journey for me.