While I was working on ELMAH.MVC v.2.0.0 I noticed a something that contradicts the way I understand how the controller resolving mechanism works. Before, I always thought that namespaces matters, but in practice I saw it otherwise.
Controller in separate class assembly
The good way of distribution re-usable software is class assembly. Suppose, I have 2 projects - one ASP.NET MVC web application (MvcApplication2), and another one is class assembly (Awesome.Mvc.Lib). Web application references the class library.
I want to have some particular controller to be exposed from Awesome.Mvc.Lib. Namely, I want to have a controller inside the class library, that would be accessible from MvcApplication2. I’ll add some ShinnyController.cs inside.
namespace Awesome.Mvc.Lib
{
public class ShinnyController : Controller
{
[HttpGet]
public string Index()
{
return "I'm in Shinny controller";
}
}
}
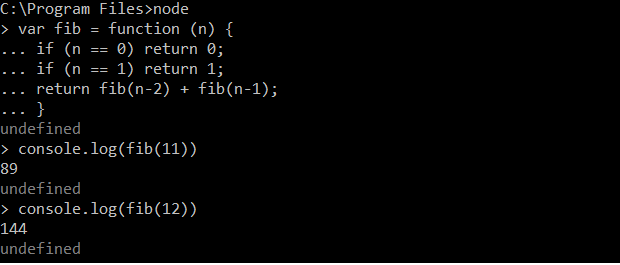
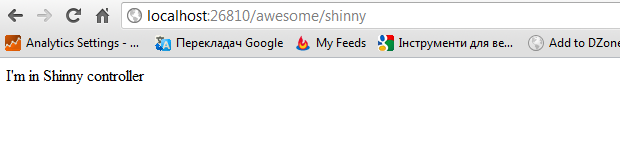
Originally, my thought was, ShinnyController will always be “invisible” for MvcApplication2, since it placed into another namespace. Meaning, if I don’t initialize a route pointing to ShinnyController, the routing mechanisms would never match it. But, if I run the application and go http://localhost:26810/shinny I will see:

This is totally unexpected to me! It turns out that default route is matching the controller/action from Awesome.Mvc.Lib class library.
routes.MapRoute(
"Default", // Route name
"{controller}/{action}/{id}", // URL with parameters
new { controller = "Home", action = "Index", id = UrlParameter.Optional } // Parameter defaults
);
What I’m expecting though is that ShinnyController.cs have to be “explicitly” routed, and ideally placed into its own sub-URL, like http://localhost:26810/awesome/shinny.
What about namespaces fallback?
I’ve asked this question on stackoverflow. Even if I had good answer, it did not make it happy. So, to get the behavior I want, I need to do the following:
- Change the default routing to explicitly mention the namespace and set fallback to false:
- Create an Area in
Awesome.Mvc.Liband configure routing to it:
public class MvcApplication : System.Web.HttpApplication
{
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
var route = routes.MapRoute(
"Default", // Route name
"{controller}/{action}/{id}", // URL with parameters
new { controller = "Home", action = "Index", id = UrlParameter.Optional }, // Parameter defaults
new[] { "MvcApplication2" }
);
route.DataTokens["UseNamespaceFallback"] = false;
}
public class AwesomeAreaRegistration : AreaRegistration
{
public override void RegisterArea(AreaRegistrationContext context)
{
context.MapRoute("Awesome_default", "Awesome/{controller}/{action}", new { action = "Index" });
}
public override string AreaName
{
get { return "Awesome"; }
}
}
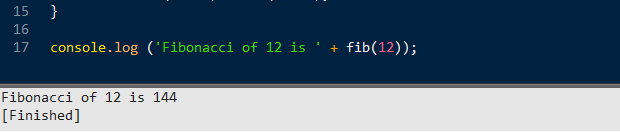
After I did so, I can reach the http://localhost:26810/awesome/shinny:
And in the same time, http://localhost:26810/shinny is getting to be rejected:
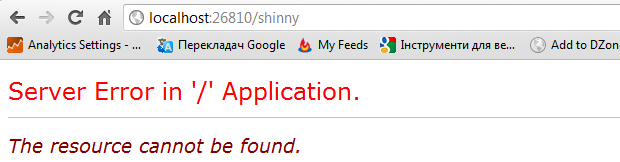
Even though, it looks like desired behavior.. It sucks.
Why it sucks?
By placing the controllers into separate assembly, I’m thinking about it’s distribution by simple bin-deployment or by Nuget. Both ways assumes, simple copy of assembly into particular location, adding references and that’s it! I don’t suppose to change default routing that comes in ASP.NET MVC applications templates.
I want to have the control of routes *inside* the class library, not outside of it (in web application). But, the default behavior of ASP.NET MVC routing is completely different. Moreover, in some cases I want users of library to be able to control the routing.
In my opinion the default behavior with UseNamespaceFallback = true is wrong. I’ll give one more example, to proof it.
I removed namespace fallback code from default route, after added new Area, called Api. Inside this Area I place one controller, called SimpleController.
namespace MvcApplication2.Areas.Api.Controllers
{
public class SimpleController : Controller
{
public string Index()
{
return "I'm simple controller from API area";
}
}
}
The controller is reachable, as expected:
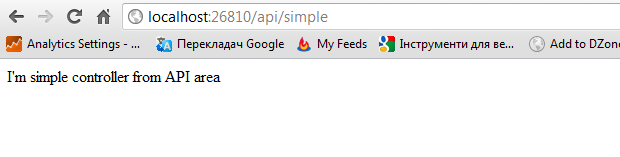
But now, I try to access /simple:
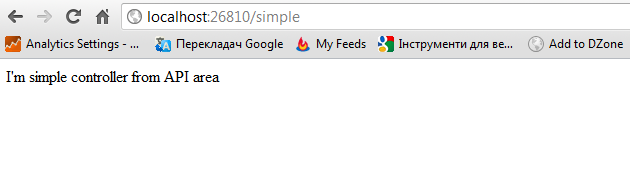
Hey WTF? The whole idea of Areas is just ruined. What I’m doing wrong?
I’m feeling very frustrated about this issue. Even though I understand why it happens, it smells like a bug for me? It works exactly the same for ASP.NET MVC 2, 3, 4. I’m asking you guys, to help to clarify the problem. What is your opinion on that? Are you agree on such default behavior?